
Suppose the variable of interest is X and the population consists of N individuals. The possible values of X are the different measurements for each individual in the population. For example, suppose the variable of interest is X=height and the population is the N = 60 students in our class. The number N = 60 is called the population size. Suppose we measure each student’s height and draw a histogram of those N = 60 measurements. In that case, the resulting distribution is the population distribution, that is, the distribution of the random variable X. The average height of all 60 students is the population mean [latex]\mu[/latex].
We often use the sample mean [latex]\bar[/latex] to estimate the population mean [latex]\mu[/latex]. However, since the observed value of [latex]\bar[/latex] varies from sample to sample, it is helpful to know the typical accuracy of this estimator. For example, how confident are we that the error in estimating [latex]\mu[/latex] by [latex]\bar[/latex] is at most 2 cm? To answer this kind of question, we need to know the distribution of the sample mean [latex]\bar[/latex].
For a population of size N, if we take a sample of size n, there are [latex]\binom[/latex] distinct samples, each of which gives one possible value of the sample mean [latex]\bar x[/latex]. The [latex]\binom[/latex] values of [latex]\bar[/latex] give the distribution of the sample mean [latex]\bar[/latex], which is also called the sampling distribution of the sample mean. A histogram of the [latex]\binom[/latex] values of [latex]\bar[/latex] shows the distribution of [latex]\bar[/latex]. However, [latex]\binom[/latex] is often so large that we are unable to consider all possible samples of size n directly. Fortunately, we can still obtain a reasonable approximation of the distribution of [latex]\bar[/latex] by obtaining a large number of random samples, say 10,000, computing each sample mean, and drawing a histogram based on our sample of the sample means. For example, if the population size is N = 60 and the sample size is n = 5, there are [latex]\binom = _C_5 = 5,461,512[/latex] different samples, many of which have different values of [latex]\bar[/latex]. Drawing a histogram of these 5,461,512 [latex]\bar[/latex] values gives the distribution of the sample mean [latex]\bar[/latex], with sample size n = 5. Moreover, the sampling distribution of the sample mean [latex]\bar[/latex] can be described in three aspects: centre, spread (variation), and shape.
Let’s consider a population consisting of 5 students. Suppose their heights (in cm) are [latex]x_1 = 155, x_2= 165, x_3=175, x_4=185, x_5=195[/latex]. The population size is N=5 and the population mean [latex]\mu[/latex] and population standard deviation [latex]\sigma[/latex] are: [latex]\begin \mu &= \frac \\ &= \frac \\ &= 175, \\ \sigma &= \sqrt< \frac< \sum (x_i - \mu )^2 > > \\ &= \sqrt > \\ &= 14.14. \end[/latex]
Consider a simple random sample of size n = 2, which means randomly picking two students from this population of five students. n = 2 is called the sample size. The number of ways we can pick two students out of five is [latex]_5C_2 = \binom = 10[/latex]. For example, one possible sample is [latex]\[/latex] which gives a value of the sample mean,
Another possible sample is [latex]\[/latex] and the corresponding value of the sample mean is:
Table 6.1 lists all possible samples of sample size n = 2, 3, 4 and their corresponding sample mean values. The mean and standard deviation of the sample mean of all possible sample sizes are also given in the table.
The mean and standard deviation of the sample mean [latex]\bar[/latex] are denoted as [latex]\mu_<\bar>[/latex] and [latex]\sigma_<\bar>[/latex] respectively. When the sample size [latex]n=2[/latex], Table 6.1 shows 10 possible values of the sample mean: [latex]160, 165, \cdots, 185, 190[/latex]; there is one value of 160 and two values of 180, giving the probabilities of [latex]\frac[/latex] and [latex]\frac[/latex] observing these two values respectively. The probability distribution and distribution histogram of the sample mean [latex]\bar[/latex] with [latex]n=2[/latex] are:
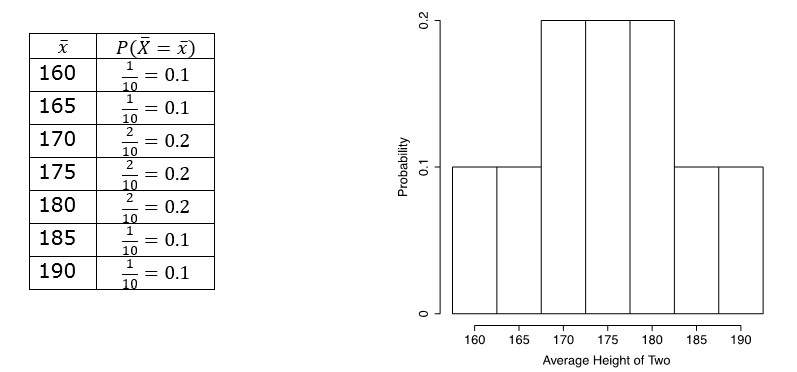
The mean and the standard deviation of the sample mean with n = 2 are:
When the sample size is n = 3, the mean and the standard deviation of the sample mean are:
When the sample size is n = 4, the mean and the standard deviation of the sample mean are:
The above results show that the mean of the sample mean equals the population mean regardless of the sample size, i.e., [latex]\mu_> = \mu[/latex], while the standard deviation of the sample mean decreases when the sample size n increases. It can be shown that when sampling without replacement from a finite population, like those listed in Table 6.1,
If we instead sample with replacement from a finite population, the standard deviation of the sample mean is
Note: If we sample without replacement, [latex]\sigma_>[/latex] is approximately equal to [latex]\frac>[/latex], as long as the sample size n is much smaller than the population size N. For simplicity of notation, we only focus on the sample without replacement case for the distribution of the sample mean in the remaining chapters.
Key Facts: Mean and Standard Deviation of the Sample Mean [latex]\color>[/latex]
For samples of size n,
These two arguments are always true for any population distribution and any sample size n.
Note: The standard deviation of the sample mean [latex]\sigma_> = \frac>[/latex] implies that as sample size [latex]n[/latex] increases, the standard deviation of the sample mean gets smaller. This is because the sample mean gets closer to the population mean and hence has a smaller variation when the sample size increases.
We discuss the shape of the distribution of the sample mean for two cases: when the population distribution is normal, i.e., the variable of interest [latex]X \sim N(\mu, \sigma)[/latex] and when the population distribution is not normal.
Suppose the random variables [latex]X_1, X_2, \dots, X_n[/latex] represent a simple random sample from a normal population distribution [latex]N(\mu, \sigma)[/latex], then the sample mean
also follows a normal distribution, regardless of the value of the sample size [latex]n[/latex]. This is a consequence of the fact that a linear combination of normal random variables is itself a normal random variable.
Example: Grade of 100 Students
Suppose a population consists of 100 students and the variable of interest is [latex]X=[/latex] student grades. Due to bonus questions, the maximum grade might be above 100. The histogram of the grades of these 100 students gives the population (or parent) distribution, or simply the distribution of [latex]X[/latex]. The mean and standard deviation of these 100 grades give the population mean and population standard deviation [latex]\mu = 70, \sigma = 10[/latex]. It is reasonable for us to assume grades follow a normal distribution since the histogram is bell-shaped and the points in the QQ plot form an approximate straight-line pattern.
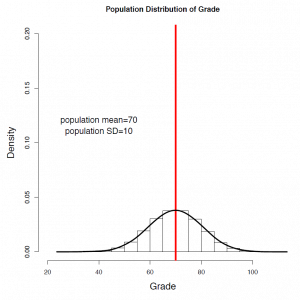 | 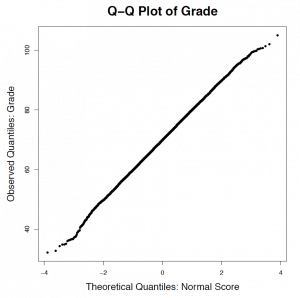 |
Figure 6.2: Density and Normal Probability Plot of Grade (Population). [Image Description (See Appendix D Figure 6.2)]
Let’s examine the distributions of the sample mean [latex]\bar[/latex] for sample size [latex]n = 2, 5, 30[/latex]. In each histogram, the red solid line indicates the population mean and the blue dashed line indicates the mean of the sample mean. Recall the steps to obtain the distribution of the sample mean:
Note that the mean and standard deviation are [latex]\mu_> = \mu = 70, \sigma_> = \frac> = \frac>.[/latex]
[latex]\sigma_> = \frac> = \frac> = 7.07[/latex] = \frac> = \frac> =4.47[/latex] = \frac> = \frac> = 1.83[/latex]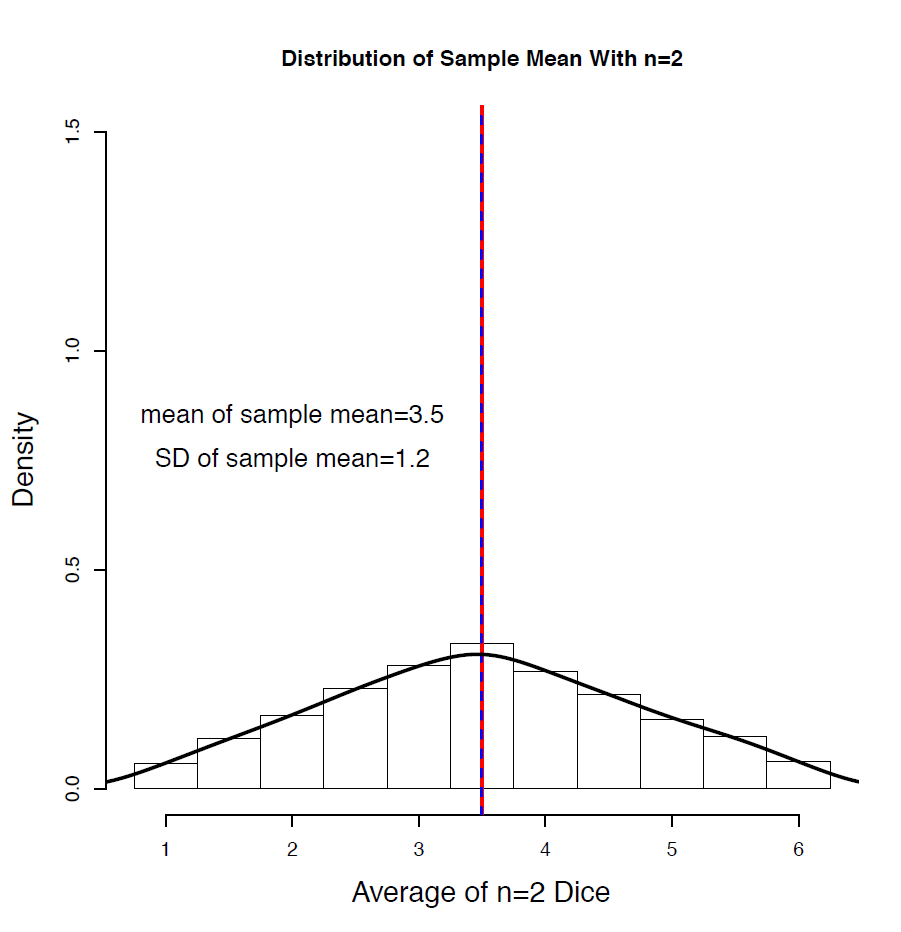

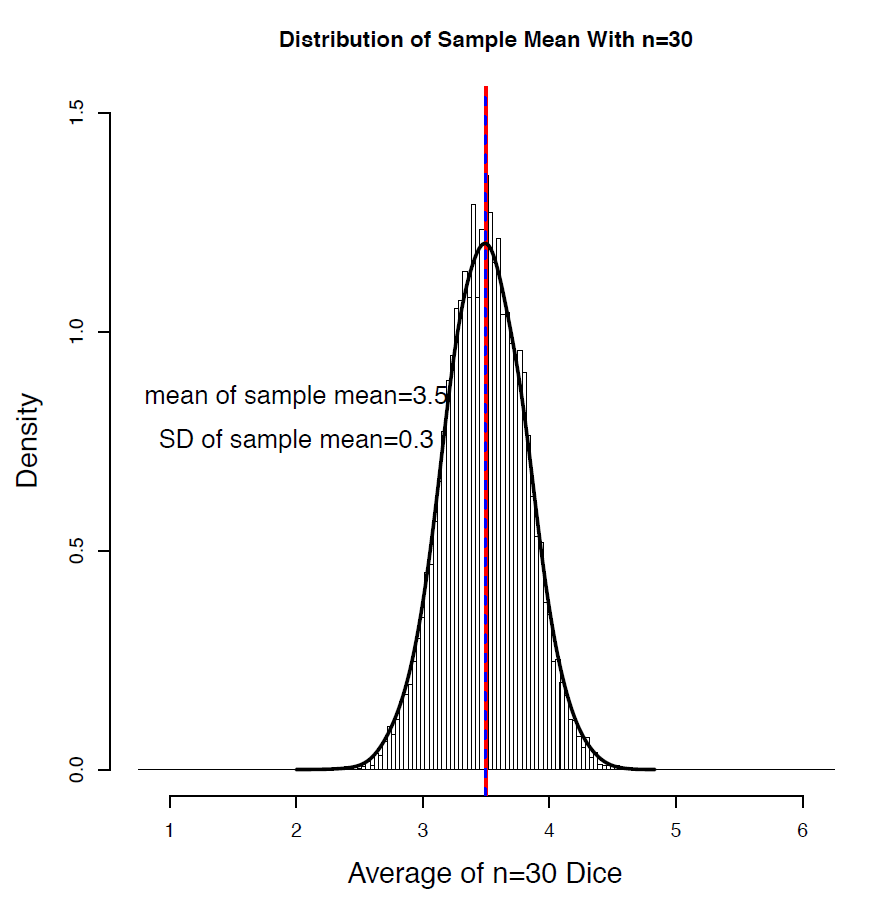
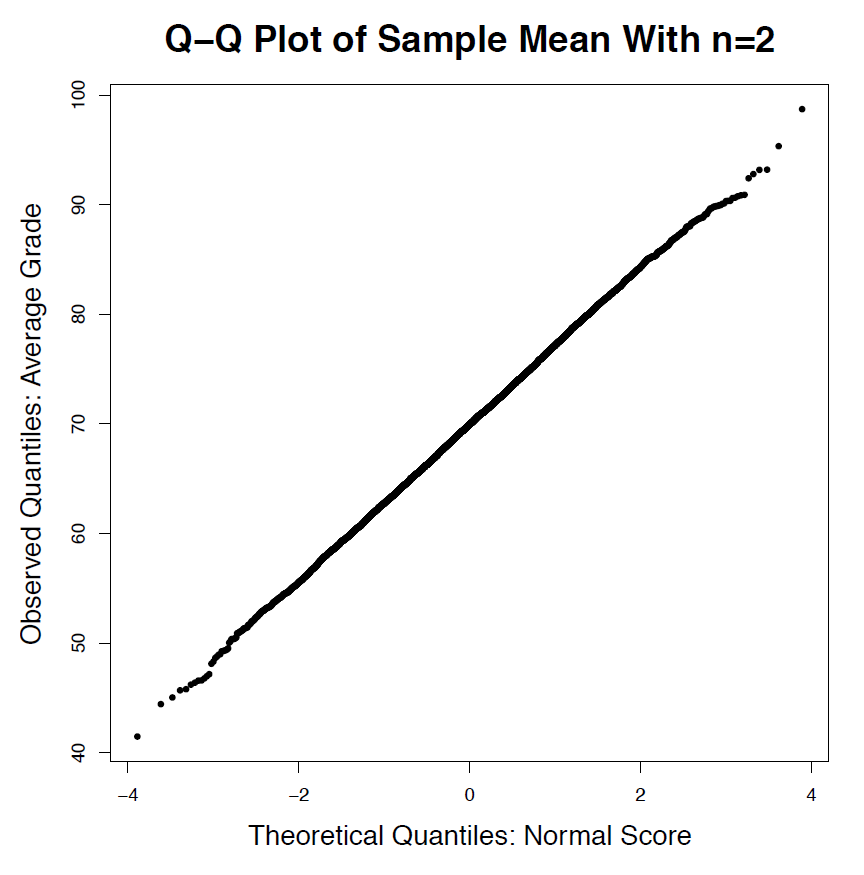
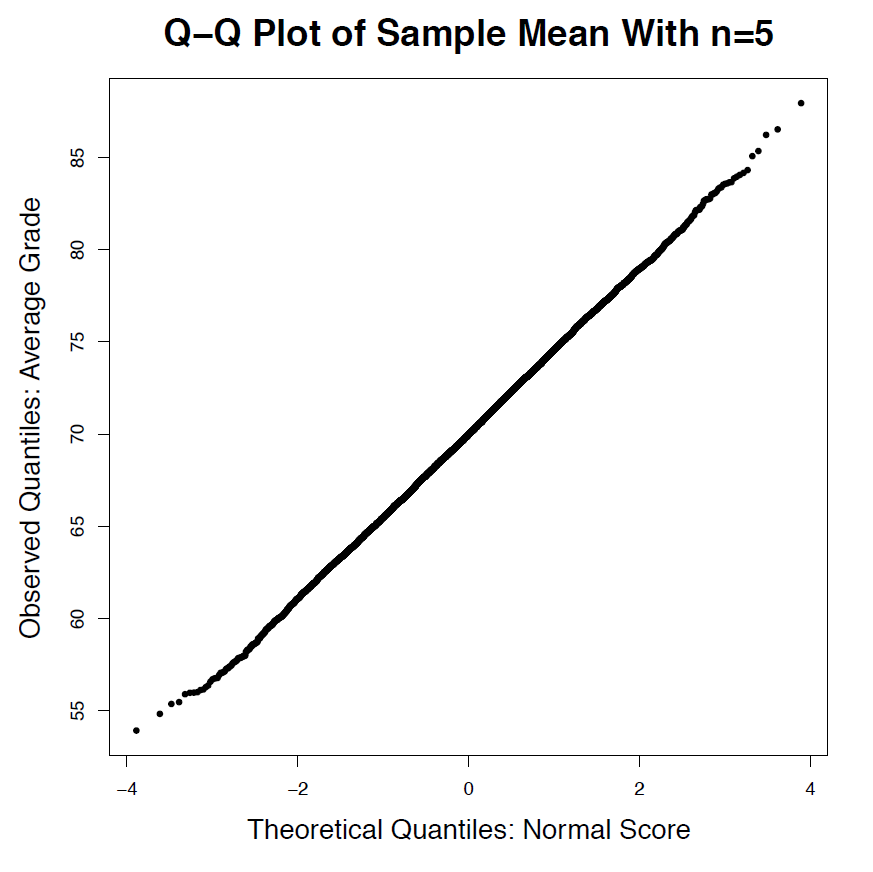
Figure 6.3: Density and Normal Probability Plot of the Average Grade (Sample Mean) for n=2, 5, 30. [Image Description (See Appendix D Figure 6.3)] Click on the image to enlarge it.
For each sample size, we can verify the following:
To illustrate two non-normal populations, we will discuss the uniform distribution (which is symmetric) and the exponential distribution (which is extremely right-skewed).
Example: Population Distribution is Uniform (Symmetric but not Normal)
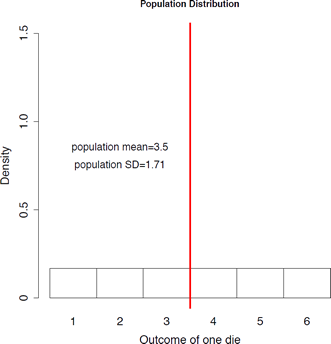
Consider rolling a fair die. Since the die is fair, each face has the same chance to be observed; therefore, the population distribution is a uniform distribution with the following probability distribution.
| [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small | [latex]\small[/latex] |
| [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small<1^2\times \frac = 1/6>[/latex] |
| [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small<2^2\times \frac = 4/6>[/latex] |
| [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small<3^2\times \frac = 9/6>[/latex] |
| [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small<4^2\times \frac = 16/6>[/latex] |
| [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small<5^2\times \frac = 25/6>[/latex] |
| [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small[/latex] | [latex]\small<6^2\times \frac = 36/6>[/latex] |
| sum=1 | sum=21/6=3.5 | sum=91/6 |
The population mean and standard deviation are calculated as follows:
[latex]\begin \mu &= \sum xP(X=x) \\ &= \frac(1 + 2+3+4+5+6) \\ &= 3.5, \\ \sigma &= \sqrt \\ &= \sqrt<\frac(1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 ) - 3.5^2> \\ &= 1.71. \end[/latex]
The uniform distribution is not bell-shaped and, hence, is not a normal distribution. Let’s examine the distribution of the sample mean with sample sizes n = 2, 5, 30, that is, the distribution of the average of n rolls of a fair die. Note that the mean and standard deviation are: [latex]\mu_> = \mu = 3.5; \sigma_> = \frac> = \frac>[/latex].